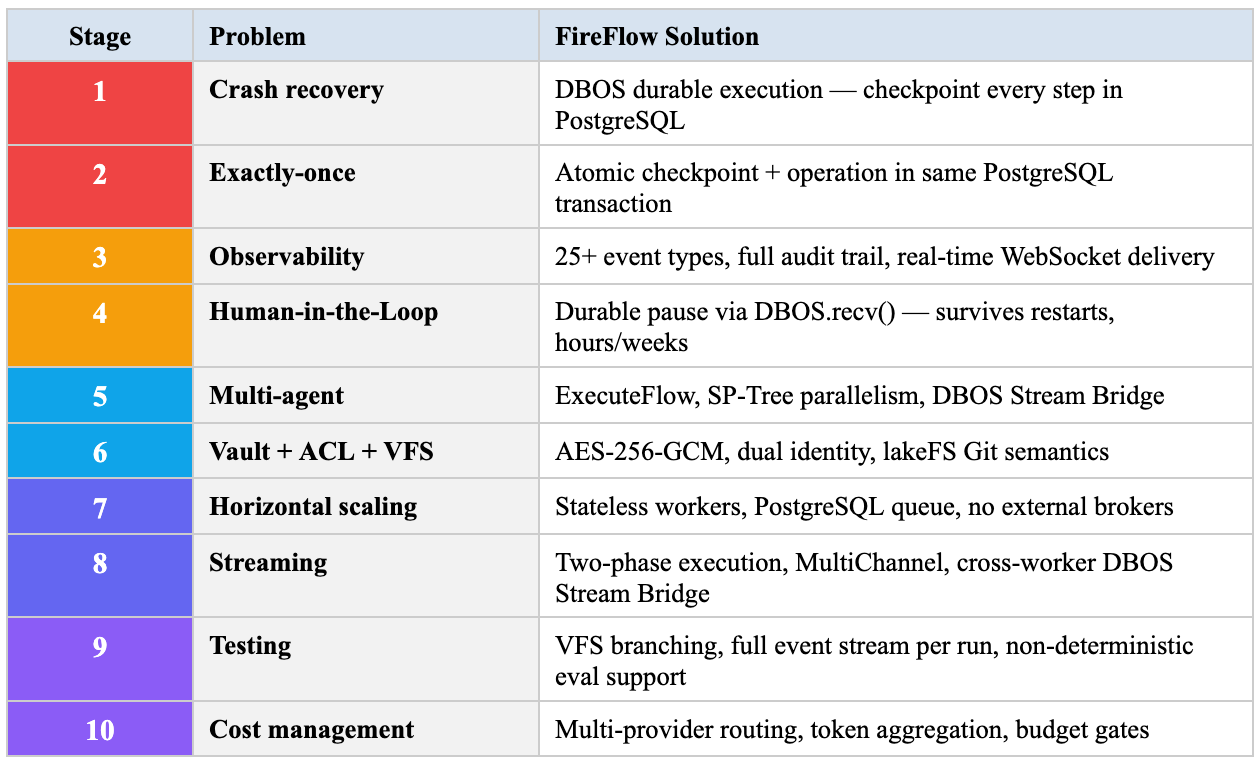
FireFlow: From Script to Agentic Operating System


Every team building AI agents passes through the same ten stages. Every stage ends with the same conclusion. At the end of the journey — the same architecture.
FireFlow is the architecture everyone arrives at. The difference: it already exists.
Stage 1: The Script Works
It starts with enthusiasm. A developer connects the Claude API in an evening, writes 50 lines of code, the agent answers questions. The demo impresses. Management gives the green light.
A week later the script goes to production. Two days after that — the first incident: the process crashed mid-request. What happened? Unknown. State lost. No logs. The client received an error.
Team reaction:
“We’ll add try/catch and a restart.”
What is actually needed:
Saving the state of each step to persistent storage with the ability to resume from the point of failure.
Cost to build in-house:
2–4 months. Requires designing a checkpoint format, database storage, recovery logic, edge-case testing (crash between writing to the database and sending a response, crash during recovery, concurrent recovery).
How it works in FireFlow:
DBOS — a durable execution system created by the authors of PostgreSQL and Apache Spark. Every workflow step is automatically written to PostgreSQL. On failure — automatic recovery from the last checkpoint. Zero code from the developer.
The industry reached the same conclusion
Temporal ($5B valuation, clients include OpenAI, Block, ADP). DBOS. Inngest. AWS Durable Functions. Cloudflare Workflows. All of them — independently — built the same thing: persistent execution with checkpoints. This is not a debatable question. It is engineering consensus.
Stage 2: Added Retry — Got Double Charges
The script recovers after failures. But now a new problem: on retry, the request to an external API goes out twice. A payment is charged twice. An email sent twice. An order created in duplicate.
Team reaction:
“We’ll add an idempotency key to every call.”
What is actually needed:
Exactly-once semantics at the infrastructure level, not in the business logic of each individual call.
Cost to build in-house:
1–3 months. Requires an idempotency token table, logic to check “already executed?” before every call, handling of timeouts (request sent, response never arrived — was it executed or not?), token expiration, coordination between instances. Airbnb published a detailed post-mortem on how they solved the double payment problem in a distributed system. The solution took months of work by an infrastructure team.
How it works in FireFlow:
DBOS writes the checkpoint inside the same PostgreSQL transaction as the step itself. If the step did not complete — the transaction rolls back entirely. If a duplicate arrives — DBOS returns the cached result. Exactly-once for database operations at the infrastructure level, without a single line of code from the developer.
Stage 3: What Is Actually Happening?
The agent is running. Sometimes. When it is not — the team spends hours on investigation. “What request came in? What data did the agent receive from the LLM? Why did it choose this tool and not another? When exactly did the error occur?”
console.log is scattered throughout the code. Logs go to stdout. No structure. Search means grep in a terminal.
Team reaction:
“We’ll add structured logging and tracing.”
What is actually needed:
Event-sourced recording of every step with full context — input data, output data, timing, identity, result.
Cost to build in-house:
2–3 months. Requires an event model (which types, what structure), a store (PostgreSQL? Elasticsearch? ClickHouse?), APIs for writing and reading, a UI for browsing, a retention policy, and indexing for fast search.
How it works in FireFlow:
Every execution generates a complete event stream in PostgreSQL. 19 flow event types (FLOW_STARTED, NODE_COMPLETED, PORT_VALUE_CHANGED...), 21 execution event types. Each event contains timestamp, nodeId, input/output data, timing. Real-time delivery via PostgreSQL NOTIFY → WebSocket. Visualised in the editor: click a node to see all data that passed through it.
Regulatory requirement
FINRA (Rules 17a-3, 17a-4) requires storage of records of all decisions. MiFID II requires real-time monitoring. EU AI Act requires an audit trail for high-risk AI systems. Without event sourcing, compliance is impossible.
Stage 4: The Agent Needs to Ask Permission
The agent has become capable enough to take actions. But not all actions can be automated: large payments, data deletion, sending emails to customers. Human approval is required.
First approach: webhook → Slack notification → person clicks a button → webhook back. Works until the process crashes between sending the notification and receiving the response. Or until the person responds three hours later and the process has long since died.
Team reaction:
“We need a task queue with persistent waiting.”
What is actually needed:
Fault-tolerant pause — the workflow stops, records a waiting point in the database, and can wait for a human response for hours, days, or weeks. Servers can restart, deploy, and scale — when the response arrives, the workflow resumes from exactly the same point.
Cost to build in-house:
3–6 months. This is one of the most complex infrastructure tasks: requires a persistent task queue, a mechanism for “freezing” process state, a mechanism for “thawing” on signal receipt, a UI for showing pending requests, timeout handling, cancellation handling, handling of multiple simultaneous waits.
How it works in FireFlow:
A2UI Interactive — a node that generates a UI card (form, buttons, data) and calls DBOS.recv(). The workflow records a waiting point in PostgreSQL. The server can restart 10 times. When the user clicks a button — whether in an hour or a week — DBOS delivers the message and the workflow continues.
Three HITL mechanisms out of the box: AG-UI Tool Calls (inline in chat), A2UI Interactive (generative UI with 18 components), MiniApp Bridge (a full web application). All three — with fault-tolerant pause.
Gartner Projection
40%+ of agentic AI projects will be cancelled by 2027. The primary reason: insufficient control and absence of a human in the loop. HITL is not optional. It is the filter between live and dead projects.
Stage 5: One Agent Cannot Handle It
Tasks become more complex. A single agent must analyse data, communicate with the customer, check compliance, and call external APIs. The context window overflows. Quality drops. Latency increases.
Team reaction:
“We’ll break it into specialized agents.”
What is actually needed:
A supervisor that distributes tasks; specialised agents, each with its own context; a mechanism for passing data between them; handling of the situation where one agent has failed; monitoring of the entire chain.
Cost to build in-house:
3–6 months. Inter-agent message protocol, task format, routing, error handling (what to do if a child agent does not respond?), coordination (wait for all or continue as ready?), state (where to store intermediate results?).
How it works in FireFlow:
ExecuteFlow — a node that calls another flow as a function. Each child is a separate DBOS workflow with its own checkpointing. Bidirectional streaming between parent and child via DBOS Stream Bridge. One child fails — the others continue (Promise.allSettled). The SP-Tree Engine automatically parallelises independent branches.
StreamFlatMap — launch a sub-flow for each stream element with concurrency control. MessageLoop — an infinite message-receiving loop for actor-style agents. Five ready-made archetypes: Event Handler, Stream Processor, Stateful Service, Supervisor, Pipeline.
Industry Data
Databricks notes that Supervisor is the most common pattern (37% of production multi-agent systems). Microsoft, Google, and AWS recommend it as the default. FireFlow implements it as a visual template.
Stage 6: Production Is Operational Discipline, Not Code
Agents are running. Several specialised agents coordinate through a supervisor. But now new problems emerge:
Secrets.
Bank API keys are stored in a .env file. One developer accidentally committed them to git. Samsung lost proprietary code through ChatGPT. Key leakage → system compromise.
Access control.
An agent created to read account balances can write transactions. No access separation. Agent goal hijacking (OWASP ASI01) → unauthorised actions.
Versioning.
Which version of the agent was running yesterday at 14:32 when the incident occurred? How do you roll back? Where is the diff between the current and previous version?
Isolation.
A flow created by one user is executed under another user’s identity. The confused deputy problem: an agent acts on behalf of User A but gains access to User B’s resources.
—
Team reaction:
“We need a vault, RBAC, git for configurations, an identity model...”
Cost to build in-house:
6–12 months. Vault (encryption, key rotation, per-user isolation), RBAC (roles, permissions, middleware), VCS for agent configurations (storage, branching, merge), identity model (who created the flow, who ran it, who has access to results).
How it works in FireFlow:
Vault: AES-256-GCM encryption per-user via HKDF-SHA256. Compromising one user’s key does not expose other users’ secrets. Transit re-encryption via ECDH when passing into execution context.
Dual Identity: every execution carries flowOwnerId (who wrote the flow) and callerId (who ran it). API keys are bound to identity, not to the flow template. Confused deputy protection: write operations use only the owner’s identity.
VFS: lakeFS-backed filesystem with Git semantics. Branches for development, tags for versions, immutable snapshots. Diff between commits. Roll back to any previous version.
ACL: owner / editor / viewer at the workspace level. Node-level access rules (allow/deny per node). Per-flow permission checking in middleware.
Security Context
Anthropic documented the first AI-orchestrated cyber-espionage campaign (September 2025): attackers used Claude for 80–90% of operations, decomposing the attack into ‘small, innocent tasks.’ This underscores the criticality of isolation and access control.
Stage 7: Scale Changes Everything
100 customers → 10,000 → 100,000. A single process cannot cope. Horizontal scaling is required. But how do you distribute workflows across workers? How do you guarantee two workers don’t pick up the same task? How do you balance load? How do you monitor a fleet of workers?
Team reaction:
“We need Kafka / RabbitMQ / Redis for queues, Kubernetes for orchestration, Prometheus for monitoring...”
What is actually needed:
Horizontal scaling without code changes, coordination through a single source of truth, automatic task distribution.
Cost to build in-house:
3–6 months + ongoing. Infrastructure: Kafka/Redis/RabbitMQ (selection, deployment, monitoring, maintenance). Coordination: distributed locking, task claiming, failover. Monitoring: Prometheus + Grafana + alerting. DevOps: Docker, K8s manifests, CI/CD.
How it works in FireFlow:
All services are stateless. State lives in PostgreSQL. Execution workers pick up tasks via SELECT FOR UPDATE SKIP LOCKED — tens of thousands of workflows per second without external brokers. Adding 10 workers increases throughput 10x. The code does not change. Kafka, Redis, RabbitMQ — not needed. PostgreSQL is the only dependency.
Workers with heterogeneous hardware: CPU for compute tasks, GPU for ML models, lightweight instances for I/O-bound operations. DBOS distributes automatically.
Stage 8: The User Waits 15 Seconds and Leaves
The agent is thinking. The LLM is generating a response. After 8 seconds — the response is ready. But the user sees a blank screen for 8 seconds, then the entire text appears at once. In 2026 this is unacceptable. Users expect text to appear token by token, as in ChatGPT.
Team reaction:
“We’ll add SSE / WebSocket for streaming.”
What is actually needed:
A complete streaming infrastructure — from the LLM API (which delivers tokens one at a time) through server-side processing (format conversion, routing, buffering) to the client (SSE/WebSocket with reconnect, backpressure, ordered delivery). And this must work end-to-end through the entire graph: the producer starts generating — the consumer is already receiving data without waiting for completion.
Cost to build in-house:
2–4 months of specialized work. SSE “covers 90% of cases” but WebSocket is needed for bidirectional communication. WebSocket is “notoriously hard to scale” — requires sticky sessions or socket brokers. Backpressure: if the LLM produces tokens faster than the network can deliver — buffer control is needed. Long-lived connections change the configuration of load balancers and timeouts.
Industry Data
Latency is the second most significant barrier to production deployment of agents: 20% of respondents named it the main problem (LangChain, 2025). Target TTFT (Time to First Token): <500ms for chatbots, <100ms for code completion.
How it works in FireFlow:
Two-phase node execution. In the preExecute phase the producer creates a MultiChannel (async broadcast channel) and notifies downstream nodes that “the stream is ready.” The consumer begins receiving data before the producer completes. LLM generates → AnthropicToAgUI converts to AG-UI events in real time → StreamEmitter writes to DBOS stream → PostgreSQL NOTIFY → WebSocket → browser. The first token appears in milliseconds.
For cross-workflow streaming (parent → child on different workers) — DBOS Stream Bridge: MultiChannel → writeStream() → PostgreSQL → readStream() → MultiChannel. Data flows between processes on different machines with delivery guarantees.
Stage 9: How Do You Test Something That Gives a Different Answer Every Time?
The agent is in production. Sometimes it responds brilliantly. Sometimes it hallucinates. Ordinary unit tests are useless: the same input produces different output. assertEqual does not work for LLM-generated text.
Team reaction:
“We’ll write eval scripts, run them 100 times, look at the percentage of correct answers.”
What is actually needed:
A framework for testing stochastic systems — multiple runs, statistical aggregation, LLM-as-judge for quality evaluation, trajectory-level metrics (not an individual response but the entire decision chain), A/B testing of agent versions on live traffic.
Cost to build in-house:
2–4 months + ongoing. Evaluation model (which metrics? PlanQuality? ToolCorrectness? PolicyAdherence?), infrastructure for multiple runs, result storage, analysis UI, CI/CD integration, alerting on degradation.
Industry Data
Quality is the number one barrier to production deployment: 32% of respondents named it the main problem (LangChain State of Agent Engineering, 1,300+ respondents). Yet only 52% of organizations have implemented evals for agents (compared to 89% for observability).
How it works in FireFlow:
VFS with Git semantics provides the infrastructure for versioning and A/B testing. Dev branch for experiments, main for production. Every execution generates a complete event stream that can be automatically analysed. FlowResearch (9 nodes) allows an agent to analyse its own results. ExecuteFlow runs test scenarios as sub-flows. A full audit trail of every run — what data the agent saw, what decisions it made, what tools it called.
Stage 10: The API Bill Arrived — and It Is Not a Typo
The agent is running. Customers are satisfied. Then the LLM API bill arrives. It is 10 times larger than expected.
96% of enterprises report that AI costs exceed initial estimates. A single uncontrolled agent can burn $300/day ($100K/year). Documented incidents: $47,000 in 11 days from an infinite loop. $8,000 over a weekend from a misinterpreted API error. $11,000 over budget after an innocent change to a system prompt — “be more helpful and contextual” increased the context window on every request.
Team reaction:
“We’ll add a rate limiter and budget monitoring.”
What is actually needed:
Per-agent and per-user cost tracking, model routing (cheap model for simple tasks, expensive for complex), budget gates with automatic shutdown, semantic caching (similar requests → cached responses), real-time cost dashboard.
Cost to build in-house:
2–4 months. Token counting per provider (different APIs, different formats), storage and aggregation, real-time alerting, model router (model selection based on task complexity), cache (vector similarity search to identify ‘similar’ requests), UI for analysis.
Industry Data
Smart routing reduces costs by 30–85% without quality loss: RouteLLM demonstrated 85% cost reduction on MT Bench. Semantic caching covers ~31% of enterprise requests, reducing cost by 40–70%.
How it works in FireFlow:
Every execution records a complete event stream with timing for every node. Multi-provider support out of the box (Anthropic, OpenAI, Gemini, DeepSeek, Groq, self-hosted) — switch between models at the graph node level. LLMUsageAggregator aggregates token usage across the entire chain. Budget checks via FFDB Query before each expensive operation. Self-hosted LLM connects as a standard HTTP node — the same graph, the same guarantees, but without external API costs.
All Ten Stages: One Architecture
The path is predictable. The architecture is inevitable.
The Architecture Everyone Arrives At:
[Visual Builder] [Execution Engine] [Durable Execution] [Event Stream]
[HITL + durable pause] [Secrets Vault] [Version Control] [ACL / Identity]
[Worker Pool] [Streaming] [Non-deterministic Testing] [Cost Management]
[Deployment: web / mobile / chat / API]
│
▼
FireFlow: 301 nodes · 43 design documents · 3+ years of development
All of this already works.Why Everyone Arrives at the Same Place
This is not a coincidence. It is a consequence of fundamental constraints.
Physics of Distributed Systems
Processes crash. Networks drop packets. Disks fill up. The only way to guarantee progress is persistent checkpoints. Temporal, DBOS, Inngest, AWS, Cloudflare — all reached the same conclusion independently.
The Nature of LLMs
Language models are non-deterministic. The same prompt can produce different results. The only way to maintain control is to record every step and give humans the ability to intervene. Event sourcing + HITL are inevitable.
Regulatory Requirements
MiFID II, FINRA, EU AI Act, and equivalent national regulators all require: audit trail, kill switch, human oversight, testing before deployment. These requirements dictate the architecture. Compliance is impossible without event sourcing, HITL, VCS, and ACL.
The Economics of Errors
Knight Capital lost $440 million in 45 minutes due to an uncontrolled algorithm. A LangChain agent burned $47,000 in 11 days in an infinite loop. The cost of one error exceeds the cost of the entire control infrastructure.
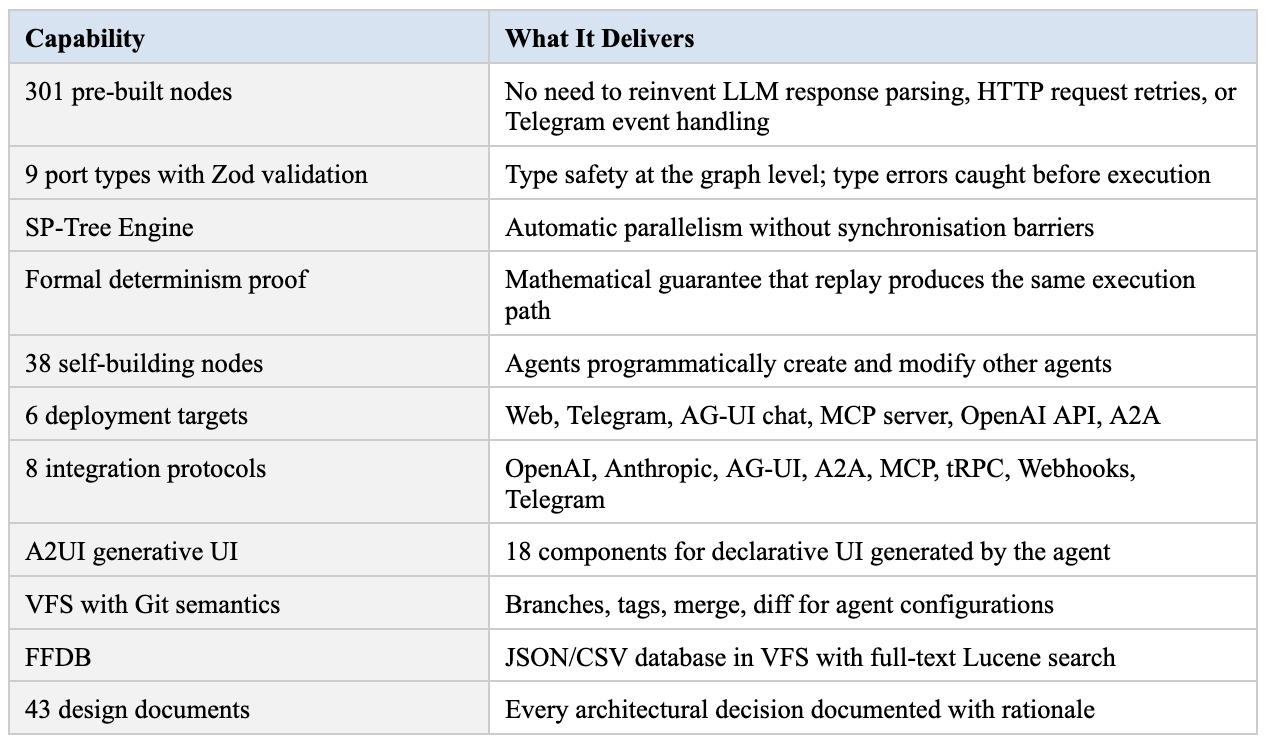
What FireFlow Adds Beyond the Necessary Architecture
Stages 1–7 lead to baseline infrastructure. FireFlow goes further.
The Cost of Repeating the Journey
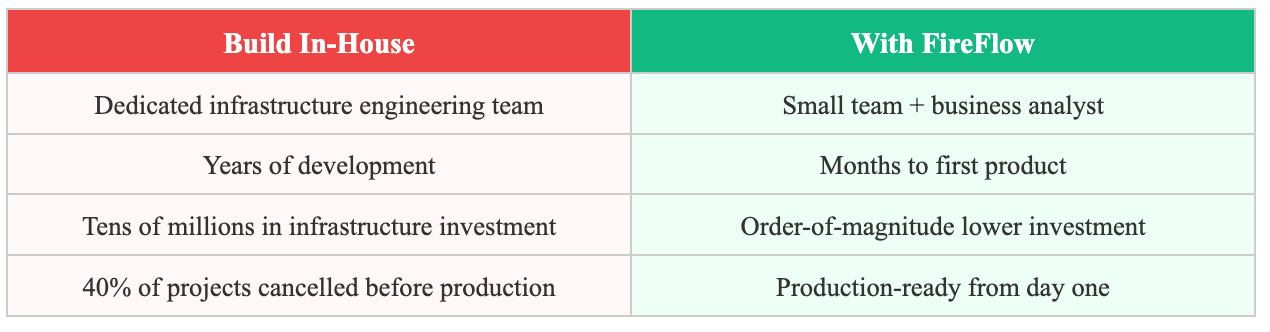
40% of agentic AI projects will be cancelled by 2027 (Gartner). Primary reasons: uncontrolled costs, unclear business value, insufficient risk control. All three causes are consequences of attempting to pass through all ten stages independently.
Conclusion
The path from script to production-ready agent system is predictable. Ten stages. Every team passes through them in the same order, encounters the same problems, arrives at the same solutions. This is not a matter of talent or resources — it is a property of the problem domain.
FireFlow is the result of completing this path in full: 3+ years of development, 43 design documents, 301 nodes, 9 port types, a formal proof of determinism, production-tested architecture built on DBOS and PostgreSQL.
The question for every team starting to build agents: repeat this journey from the beginning — or start from the finish line?
Sources: LangChain State of Agent Engineering 2025 (1,300+ respondents); Gartner AI Agent Predictions 2027; Databricks multi-agent architecture report; Airbnb distributed payments engineering blog; RouteLLM cost reduction research; IBM X-Force Threat Index 2026.