FireFlow: AI Agent Security Architecture


The Core Question: Where Does the Agent Run?
In 2026, the security landscape for AI agents is defined by a single architectural decision: where does the agent execute?
The IBM X-Force Threat Index (February 2026) formalized what security researchers had been demonstrating for two years: every successful prompt injection against an AI agent with execution capabilities is effectively a Remote Code Execution (RCE). OpenAI acknowledged in December 2025 that prompt injection in AI agents “may never be fully solved”.
This means the question is not whether an agent can be deceived — but what the agent has access to when it is.
Two Architectural Approaches
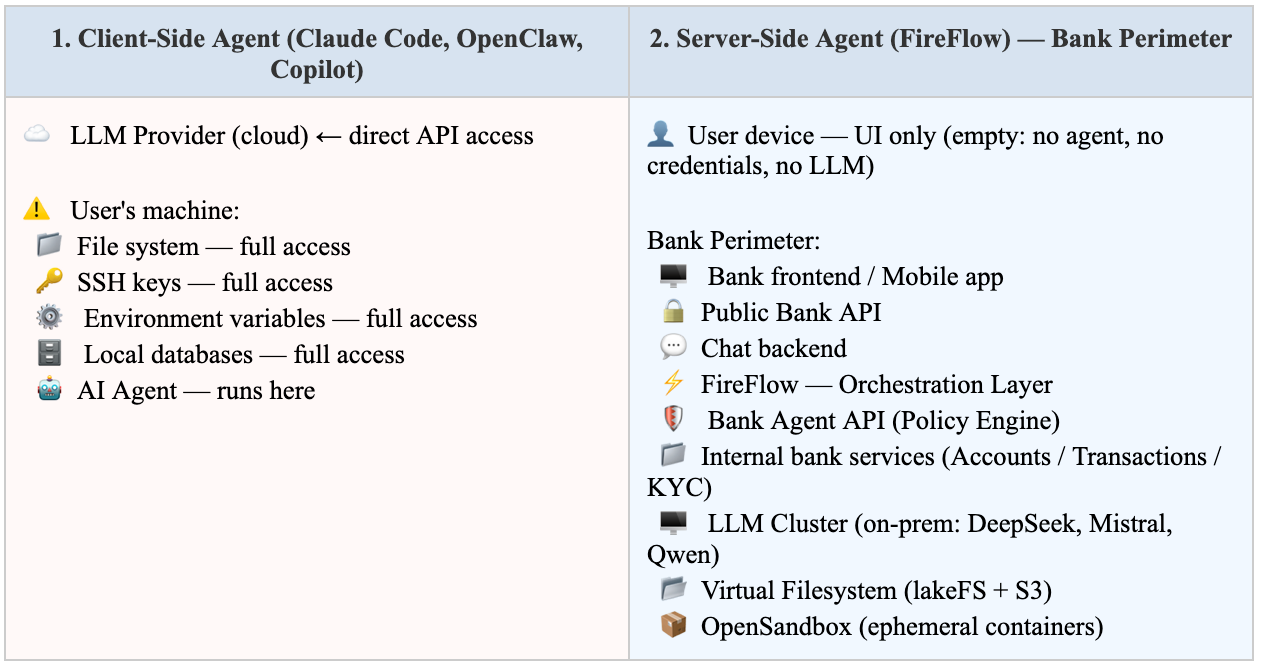
In the Client-Side model, a compromised agent equals a compromised machine. In FireFlow’s Server-Side model, a compromised agent is contained within an isolated execution sandbox with no access to user devices, host systems, or unscoped resources.
Core Principle
FireFlow is not an LLM with access to your infrastructure. It is your infrastructure with controlled access to an LLM.
Real-World Incidents: Why Architecture Decides Everything
These are not theoretical risks. Every major client-side AI agent platform was compromised between 2024 and 2026.
Claude Code — RCE via Project Configuration (February 2026)
CVE-2025-59536 (CVSS 8.7): Opening a malicious repository triggers remote code execution before the user accepts any dialogue. A poisoned .claude/settings.json injects shell commands into lifecycle hooks that execute automatically.
CVE-2026-21852 (CVSS 5.3): A malicious repository overwrites ANTHROPIC_BASE_URL, sending Anthropic API keys to an attacker-controlled server.
Root cause: the agent runs on the user’s machine and trusts configuration files.
OpenClaw — 135,000 Exposed Instances (January 2026)
CVE-2026-25253 (CVSS 8.8): Zero-click WebSocket hijack. The agent bound to 0.0.0.0:18789 by default — visiting a malicious site while OpenClaw was running gave attackers full shell access.
512 vulnerabilities in the first audit. 820+ malicious packages in ClawHub (the marketplace), including keyloggers and credential stealers. 135,000+ publicly accessible instances across 82 countries.
Root cause: agent runs locally with broad system privileges. No sandbox, no network isolation.
IDEsaster — 100% of AI Tools Vulnerable (December 2025)
Researcher Ari Marzouk tested all major AI development agents: GitHub Copilot, Cursor, Windsurf, Kiro.dev, Zed.dev, Roo Code, Junie, Cline. 100% were vulnerable to the chain: prompt injection → auto-approved tool calls → security boundary bypass. 24 CVEs issued.
Microsoft Copilot — Zero-Click Data Leak
EchoLeak (CVE-2025-32711): An attacker sends a crafted email. When Copilot processes it, data from the user’s mail, calendar, and files is exfiltrated to the attacker’s server. Without a single click.
Reprompt Attack: Persistent session exfiltration — data continues leaking even after Copilot is closed.
The U.S. Congress banned Copilot use by House employees.
Financial Fraud via AI Agent — $2.3M
Attackers embedded hidden instructions in email content that caused a financial organisation’s AI assistant to approve fraudulent transfers totalling $2.3 million. Deloitte projects AI fraud losses of up to $40 billion by 2027 in the United States alone.
n8n (CVSS 10.0) and Langflow — Full Platform Takeover
Both AI workflow platforms — comparable in purpose to FireFlow — contained critical vulnerabilities permitting unauthenticated remote code execution and complete system takeover.
FireFlow’s Defense-in-Depth Architecture
FireFlow implements defense-in-depth through multiple independent architectural layers. Each layer operates autonomously — compromising one does not compromise the others.
Defense Layers (left → right):
[1. Execution Isolation]
→ [2. Deterministic Engine]
→ [3. Virtual Filesystem]
→ [4. Secret Encryption]
→ [5. Dual Identity & ACL]
→ [6. Human-in-the-Loop]
→ [7. Audit Trail]Layer 1: Execution Isolation
The agent never runs on the user’s machine.
Every agent execution in FireFlow is an isolated DBOS workflow on a dedicated server worker:
Process isolation: the Execution API and execution workers are separate processes with different service factories. The API cannot execute workflows — it only enqueues tasks. Workers pick up and execute.
No shell access: nodes cannot spawn processes, invoke /bin/bash, or run arbitrary commands on the host.
No host filesystem: agents work exclusively with the Virtual File System (VFS) — an abstraction backed by lakeFS. Even a fully compromised agent cannot read /etc/passwd or write to /var/.
No environment variables: nodes receive only explicitly injected services (context.services), not process.env.
AsyncLocalStorage: each node runs in its own isolated async context. Parallel nodes cannot read each other’s state.
Docker containerisation: workers run as a non-root user (UID 1001) on Alpine Linux. The production image contains no package manager, no source code, no shell.
When arbitrary code execution is required, the architecture provides OpenSandbox — ephemeral containers destroyed after execution. No persistence, no network access to other services. Container sandbox integration is the next development milestone.
Execution API / Worker Separation:
[Execution API] [Execution Worker]
┌────────────────────┐ ┌─────────────────────────────┐
│ Client interface │ │ Full DBOS runtime │
│ Does NOT execute │ ─PostgreSQL──▶ │ Picks from PostgreSQL queue │
│ workflows │ queue │ Checkpoints every step │
│ Only enqueues │ │ Auto-recovery on failure │
└────────────────────┘ └─────────────────────────────┘What this prevents: CVE-2025-59536 (Claude Code RCE), CVE-2026-25253 (OpenClaw WebSocket hijack), EchoLeak (Copilot data leak). None of these attack vectors exist in a server-side architecture — there is no user machine to compromise, no local configs to poison, no local credentials to steal.
Layer 2: Deterministic Execution Engine
Every execution is reproducible and auditable.
SPTree (Series-Parallel Tree) — FireFlow’s execution engine — provides a determinism guarantee backed by a formal specification. In practice: given the same flow with the same inputs run twice, the sequence of events, calls, and results will be identical. This is not ‘usually reproducible’ — it is a guarantee at the engine level. If a regulator requests reproduction of an incident, the system will show exactly the same execution path as the original.
Determinism is achieved through strict execution ordering in three phases:
Three-Phase Deterministic Execution:
[preExecute] [execute] [postExecute]
Nodes initialised Parallel execution of Ordered await by
in sorted order → independent branches → sorted node IDs
(by node ID) │
Deterministic ▼
DBOS registration Deterministic result
Determinism is critical for:
Auditability: any past execution can be precisely reproduced for investigation.
DBOS replay: on worker failure, execution continues from the last checkpoint along the same path — without duplicating side effects.
Regulatory compliance: a regulator can verify that the agent did exactly what is recorded in the audit trail.
Exactly-once semantics for business logic:
DBOS commits each step’s result and checkpoint in a single atomic PostgreSQL transaction. If the process crashes, PostgreSQL rolls back the entire transaction. No double payments, no lost state.
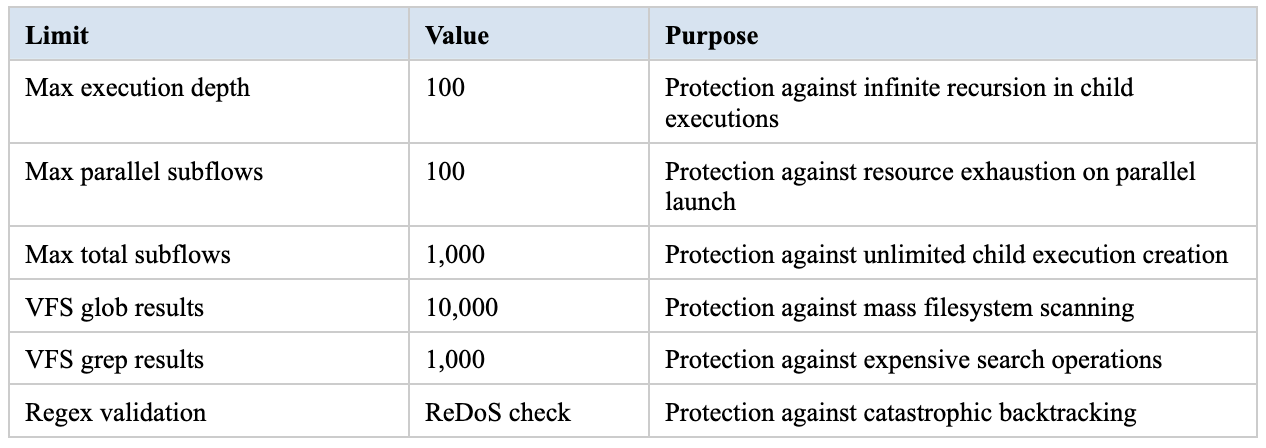
Engine-controlled resource limits:
Layer 3: Virtual Filesystem (VFS)
Agents never work with real filesystems.
The FireFlow VFS is a Git-style versioned filesystem backed by lakeFS + S3. Each agent works within an isolated workspace with explicit, granular access rights.
VFS — Three-Level Access Model + Key Properties:
Access Levels: Key Properties:
┌──────────────────────────┐ • Each workspace = separate lakeFS repository
│ Owner │ Read/Write/Admin│ • Staged writes: explicit commit() required
│ Editor │ Read/Write │ • {userId} substituted server-side only
│ Viewer │ Read only │ • Advisory locks with mandatory timeout
│ Public │ Read only │ • Presigned S3 URLs with limited lifetime
└──────────────────────────┘ • Git semantics: branches, tags, diff, rollback
Permission check order:
Is the user the workspace owner? → Full access
Is the workspace public and the request a read? → Allow read
Is the user an invited collaborator? → Apply role
Is this an app-scoped session (MiniApp)? → Apply VFS prefix rules
Otherwise → Deny
Security properties:
Workspace isolation: each workspace is a separate lakeFS repository. At execution start, the agent receives access only to a snapshot unique to the user + agent + execution combination. One client’s data is physically inaccessible to another client’s agents.
Staged writes: all file changes are staged (like git add), requiring an explicit commit() to persist. A crashed agent does not corrupt data.
Server-side template substitution: {userId} in app rules is substituted only on the server — a client cannot forge a path like ff://saves/OTHER_USER/.
Unified error message: ‘Not found or access denied’ — prevents oracle attacks on resource existence.
Advisory locks: the fireflow_ffdb_locks table in PostgreSQL prevents concurrent data corruption with a mandatory timeout (no permanent locks).
Presigned S3 URLs: files are delivered via time-limited signed URLs, not through direct storage access.
Git semantics: full version history, branches, tags, diff, rollback. Every change is traceable.
Layer 4: Secret Management (Vault)
Secrets are encrypted at rest, re-encrypted in transit, and never exposed to agents in plaintext.
Two-Layer Encryption Architecture:
AT REST (AES-256-GCM): IN TRANSIT (ECDH P-256):
Master Key Ephemeral P-256 key pair
│ │
HKDF-SHA256 + userId ECDH shared secret
│ → HKDF-SHA256
Per-user 256-bit key │
│ AES-256-GCM
AES-256-GCM + 12B random nonce │
│ Encrypted blob
[nonce | ciphertext | auth tag] for execution context
stored in PostgreSQL
Plaintext exists ONLY in server memory at the moment of re-encryptionAt rest (AES-256-GCM):
Master key → HKDF-SHA256 → per-user 256-bit key (info string: fireflow-vault:{userId})
Each secret is encrypted with a unique 12-byte random nonce
Per-user keys: compromising one user’s key does not expose other users’ secrets
In transit (ECDH P-256):
An ephemeral P-256 key pair is generated for each execution
ECDH shared secret → HKDF-SHA256 → AES-256-GCM
Plaintext exists only momentarily in server memory — never on disk, never in logs, never in plaintext over the network
Secret access control:
Secrets are bound to the owner’s identity (userId)
For execution: owner must match flowOwnerId or callerId
Single database query with a single error message (no oracle attacks)
SecretPort type in the UI — masked/write-only: agents see encrypted blobs, never plaintext
Layer 5: Dual Identity and Access Control
Every execution carries two identities. The agent cannot exceed the scope of either.
Dual Identity Model:
Execution carries: Access checks:
┌─────────────────────┐ Read: flowOwnerId → fallback callerId
│ flowOwnerId │ Write: flowOwnerId ONLY (no fallback!)
│ (who created flow) │ Secret: owner ∈ {flowOwnerId, callerId}
├─────────────────────┤
│ callerId │
│ (who triggered run) │
└─────────────────────┘This dual-identity model solves the confused deputy problem — where an agent created by User A accidentally (or maliciously) accesses resources belonging to User B:
Read: first flowOwnerId; if no access — fallback to callerId (enables flow-as-a-service)
Write: only flowOwnerId is checked — no fallback to caller. A service flow cannot write to the caller’s workspace
Secrets: owner must be in [flowOwnerId, callerId] — single query, no retry chain
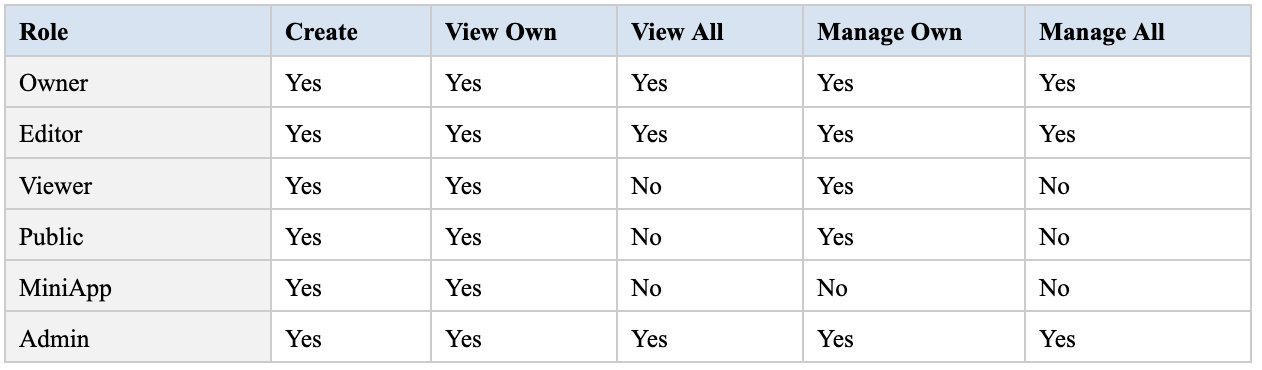
ACL Matrix for Executions:
Pre-filled values — the LLM cannot override security parameters:
When a flow designer connects a port (e.g., workspaceId, branch), that value becomes pre-filled and is removed from the LLM schema. The agent literally cannot see or change it:
Pre-Filled Value Enforcement:
Designer connects: workspaceId = 'WS_SECURE', branch = 'main'
LLM schema contains: { path: string } ← only unconnected port
LLM attempts: { path: 'file.txt', workspaceId: 'HACKED' }
Actual execution: workspaceId = 'WS_SECURE' (enforced), path = 'file.txt'Layer 6: Human-in-the-Loop (HITL)
Critical actions require explicit human approval. The system waits indefinitely — servers may restart and the workflow will resume.
FireFlow provides three HITL mechanisms, all built on DBOS durable execution:
HITL Flow:
[A2UI Interactive] ─┐
[AG-UI Tool Calls] ─┼──▶ Agent executes action
[MiniApp Bridge] ─┘ │
DBOS.recv()
Execution paused — checkpoint in PostgreSQL
│
Waiting for human response
(seconds ... weeks)
│
DBOS.send()
Workflow resumes from exact checkpointA2UI Interactive Surfaces
The agent generates a declarative UI (forms, buttons, cards from 18 component types) and calls DBOS.recv(). Execution pauses with a checkpoint in PostgreSQL. The user sees the interface, makes a decision, clicks. DBOS.send() delivers the response. Workflow resumes from the exact checkpoint. Servers can restart 10 times during the pause. Deployments can occur. The workflow will continue when the human responds — whether in 30 seconds or 3 weeks.
AG-UI Tool Calls
Inline confirmations in the chat interface. The agent proposes an action — the user approves or rejects.
MiniApp Bridge
Full web applications embedded in flows. Complete UI for complex approval procedures (e.g., multi-level transaction authorisation).
Gartner projects that 40%+ of agentic AI projects will be cancelled by 2027, primarily due to insufficient human oversight. HITL is not optional — it is the filter between deployed and cancelled projects.
Layer 7: Complete Audit Trail
Every action is recorded. Every decision is traceable. Immutable. Queryable.
FireFlow’s event-sourced architecture records every execution step in PostgreSQL:
Execution events: EXECUTION_CREATED, FLOW_STARTED, NODE_COMPLETED, PORT_VALUE_CHANGED, EDGE_TRANSFER, CHILD_EXECUTION_STARTED, STREAM_PUBLISHED, DEBUG_BREAKPOINT_HIT, and others — 25+ types covering every stage of execution
VFS events: FILE_MODIFIED, COMMITTED, BRANCH_CREATED, COLLABORATOR_ADDED, and others — complete lifecycle of files and workspaces
AG-UI events: generation streaming, tool calls, user actions — for real-time chat interfaces
Each event contains: timestamp, node ID, input data, output data, execution time, identity (who initiated).
Properties:
Immutability: events are append-only in PostgreSQL — no retroactive changes
Deterministic ordering: sequential indices assigned at emission time
Real-time streaming: PostgreSQL NOTIFY → WebSocket → monitoring dashboards
Time-travel debugging: inspect the complete state of any operation at any point in history
Recovery audit: the fireflow_execution_recovery table logs all failures and recoveries
For compliance: click on any node in the visual editor and see what data the agent received, what it decided, what output it produced, who approved it, and when. Not ‘we believe the agent operated correctly’ — but ‘here is the exact record.’
Network Architecture: Data Does Not Leave the Perimeter
Bank Perimeter Architecture:
👤 User device ──▶ Bank Frontend / Mobile App
│
Public Bank API
│
┌───────────────┐
│ FireFlow │
│ Orchestration │
└──────┬────────┘
┌────────────────┼────────────────┐
│ │ │
Bank Agent API LLM Cluster Virtual FS
(Policy Engine) (on-prem: (lakeFS + S3)
│ DeepSeek, Workspace 1
Internal Bank Mistral, Workspace N
Services: Qwen) OpenSandbox
Accounts (ephemeral
Transactions containers)
KYC/AMLSelf-Hosted LLM Cluster
Customer data never leaves the bank’s infrastructure:
FireFlow is LLM-agnostic: any OpenAI-compatible model can be connected — self-hosted (DeepSeek, Mistral, Qwen, etc.) or cloud-based. Different models can be used for different tasks within a single workflow.
When deployed on-premises, customer data physically does not leave the bank’s perimeter — requests go to models inside the infrastructure.
Proxy routing: an allowlist of approved domains ensures traffic goes only to permitted endpoints.
Smart routing: a lightweight model for classification, a powerful one for reasoning — reducing costs by 30–85% without quality loss.
Bank Agent API — The Final Perimeter
This is an additional security layer between FireFlow and the bank’s real transactional systems. Even if all other layers were somehow compromised, the Bank Agent API enforces rules that no agent can bypass:
Bank Agent API — Policy Engine:
FireFlow request for action
│
┌───────────────────────────────────────────────────┐
│ Bank Agent API — Policy Engine │
│ ┌──────────────┐ ┌───────────────┐ │
│ │ Amount limits│ │ Merchant / │ │
│ │ per-op/day/ │ │ counterparty │ │
│ │ per-category │ │ whitelists │ │
│ └──────────────┘ └───────────────┘ │
│ ┌──────────────┐ ┌───────────────┐ │
│ │ Rate limiting│ │ Fraud │ │
│ │ max ops per │ │ detection │ │
│ │ time unit │ │ integration │ │
│ └──────────────┘ └───────────────┘ │
│ ┌──────────────┐ ┌───────────────┐ │
│ │ Dual auth: │ │ Time-based │ │
│ │ HITL + policy│ │ rules / block │ │
│ │ check │ │ outside hours │ │
│ └──────────────┘ └───────────────┘ │
└───────────────────────────────────────────────────┘
│ │
Approved transaction Rejected by policy engine
The key principle: Bank Agent API does not trust FireFlow in exactly the same way it does not trust any external service. It enforces banking business rules independently. FireFlow orchestrates the workflow; Bank Agent API enforces financial rules. Two independent systems — both must approve.
Network Isolation
FireFlow accepts requests only from the bank’s Public API — not directly from users
Agent nodes make API calls only to endpoints configured in the flow graph — the administrator controls which node types are available in the builder
Outbound traffic is defined by the set of nodes in the graph: there is no mechanism for an LLM to dynamically call an arbitrary endpoint not embedded in the flow
MiniApp iframes have a CSP blocking fetch(), XMLHttpRequest, and direct WebSocket — all communication goes through a validated bridge
Webhooks are verified via HMAC-SHA256 with constant-time comparison — protection against timing attacks
Authentication tokens have limited lifetimes: session — 30 days, execution-scoped — 1 hour, demo — 7 days
API keys are automatically masked in error messages ([REDACTED]) — preventing credential leakage via logs
Prompt Injection Defense at the Platform Level
Prompt injection is the OWASP #1 risk for LLM applications for two consecutive years. OpenAI acknowledges: ‘prompt injection may never be fully solved.’ Palo Alto Unit 42 confirms: ‘soft’ defences (prompt engineering, fine-tuning) reduce risk but cannot deterministically block all attacks, because LLMs fundamentally do not separate data from instructions.
The only reliable strategy is defence-in-depth: multiple independent layers, each reducing the attack surface.
Architectural Defense: Plan-Then-Execute
FireFlow implements the Plan-Then-Execute pattern at the architectural level. In the visual editor, the flow graph is the execution plan. LLM nodes can generate data but cannot change the graph structure — which nodes are called, in what order, with what permissions. This is a fundamental distinction from client-side agents, where the LLM decides which tools to call.
Additionally, pre-filled values (described in Layer 5) exclude security-critical parameters from the LLM schema — the agent literally cannot see fields like workspaceId, branch, or accountId if they are connected by the flow designer.
Next Step: ML Classifiers as Pipeline Nodes
FireFlow’s architecture is designed so that ML prompt injection detection models integrate naturally as standard nodes in the processing pipeline. The node system and execution engine already provide all the necessary infrastructure — what remains is implementing specific wrapper nodes:
Prompt Injection Defence Pipeline:
User input
│
[Input Guard (ML classifier)]
│ │
safe │ injection detected → Blocked + alert
│
[Spotlighting (marking untrusted data)]
│
[LLM node]
│
[Output Guard (response check)]
│ │
safe │ leakage detected → Blocked + alert
│
[HITL Gate (action approval)]
│
ResultInput Guard
An ML model (Meta Prompt Guard 2, ProtectAI DeBERTa-v3, IBM Granite Guardian) classifies incoming text as benign / injection / jailbreak. Latency: 7–40ms on GPU. Open-source models, deployed on-premises — data does not leave the perimeter.
Spotlighting
A Microsoft Research technique whereby untrusted content (user input, documents, emails) is marked with special tokens before being passed to the LLM, allowing the model to distinguish instructions from data. In Microsoft’s tests this reduces attack success rates from ~50% to under 3%.
Output Guard
Checks the LLM response for leakage of system prompts, canary tokens, PII, and attempts to inject into downstream systems. Uses both ML classifiers and deterministic checks (regex, canary token matching).
Kernel-Level Enforcement
The key advantage of the flow-based architecture: protection can be enforced at the execution engine level, so even the flow creator cannot bypass it. The execution engine already supports the infrastructure for mandatory pipelines — the same mechanism that enforces pre-filled values and typed port validation. The next step: the platform administrator defines a mandatory security pipeline for all LLM calls. The engine automatically wraps each LLM node with protective steps — input scan, spotlighting, output validation. This is not an add-on that a developer can forget to include. It is an infrastructure policy built into the kernel.
PII Anonymisation
Bank customer personal data must not enter the LLM context. Even with self-hosted models, the principle of least privilege requires that the model sees only the data necessary for the task — and in anonymized form.
FireFlow’s flow-based architecture makes anonymisation a natural part of the pipeline — each data processing stage is represented as a separate node, and the entire chain can be visually inspected and enforced at the platform level.
Pattern: Anonymise → LLM → Deanonymize
The industry-standard anonymisation pipeline for LLM workflows is a three-phase process:
Anonymise → LLM → Deanonymise Pipeline:
Request with PII Response to user
(Robert Merton, → [PII Detect] → [PII Anonymise] → [LLM] → [PII Deanonymise] → (with real data)
4276 **** **** 1234, (NER model (replace with (sees only (restore originals
+4798855544222) finds entities) surrogates) anon. text) from mapping table)Phase 1 — PII Detect:
An NER model (Presidio, GLiNER, BERT-based) scans text and identifies personal data — names, phone numbers, emails, card numbers, IBANs, tax IDs, addresses. Critical for the financial sector: support for PAN (Primary Account Number), account numbers, routing numbers, and transaction data.
Phase 2 — PII Anonymize:
Identified entities are replaced with surrogates. Replacement strategies:
Realistic surrogates (Faker) — ‘Robert Merton’ → ‘Merton Miller’, card number → another valid number. The LLM receives natural text; response quality is unaffected.
Tokenization — replacement with [PERSON_1], [CARD_1]. Simpler, but less natural for the LLM.
Encryption — AES encryption with reversible decryption.
The mapping table ({surrogate → original}) is stored in the execution context — ephemeral, per-execution, not persisted.
Phase 3 — PII Deanonymize:
In the LLM response, surrogates are replaced with originals from the mapping table. The user sees the final response with real data. The LLM never saw the real data.
Kernel-Level Enforcement
Like prompt injection — anonymization is designed for enforcement at the execution engine level. The infrastructure for this already exists (typed ports, execution context, service injection); specific PII nodes are the next implementation milestone:
The administrator enables a mandatory PII pipeline for all LLM calls
The engine automatically wraps each LLM node: PII Detect → PII Anonymise → LLM → PII Deanonymize
The flow creator cannot bypass this policy — they simply connect the LLM node, and the PII wrapper is added by the engine transparently
Configurable compliance profiles: GDPR (full redaction of names and email), PCI DSS (masking PAN to first 6 + last 4), HIPAA (encryption of medical data)
Why This Is Only Possible in a Server-Side Architecture
In client-side agents (Claude Code, Copilot), data is sent to the LLM directly from the user’s machine. The organization cannot insert a PII filter between the user and the LLM provider — it has no control over that channel. In FireFlow, all LLM calls pass through the execution engine inside the bank’s perimeter. This is the only point through which data reaches the LLM — and at this point, anonymization can be guaranteed.
User-Scoped Access to Banking APIs
When integrating with banking systems, it is critical that customer API keys and credentials are protected from all parties — including platform administrators and flow creators.
Principle: No Party Sees Another’s Keys
User-Scoped Vault + Forward Secrecy:
Client saves credentials
→ User-Scoped Vault (AES-256-GCM, per-user key)
│
Execution starts → Ephemeral ECDH P-256 key pair generated
│
Re-encryption: at-rest → transit format via ECDH shared secret
│
Plaintext in worker memory ONLY during Bank API call
│
After execution: ephemeral key DESTROYED
Audit log: encrypted payload only (unreadable without key)
→ Forward secrecy: even full DB dump cannot decrypt past executionsWho does NOT have access to customer credentials:

This mechanism uses the same cryptographic infrastructure described in Layer 4 (Vault) — AES-256-GCM at rest + ECDH P-256 in transit. The distinction is that for banking credentials, forward secrecy is guaranteed through ephemeral execution-scoped keys.
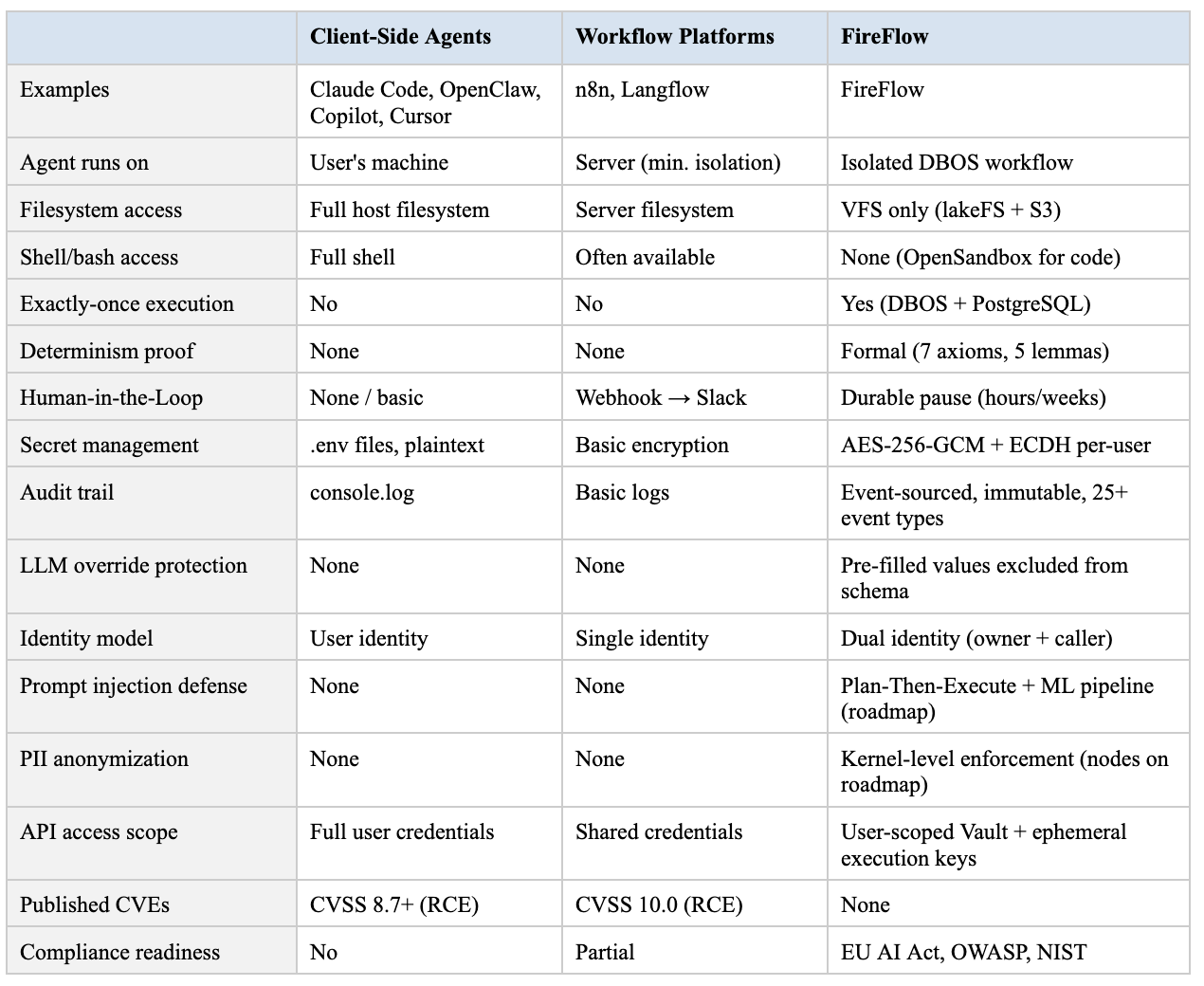
Comparison with Alternatives
Standards and Regulatory Compliance
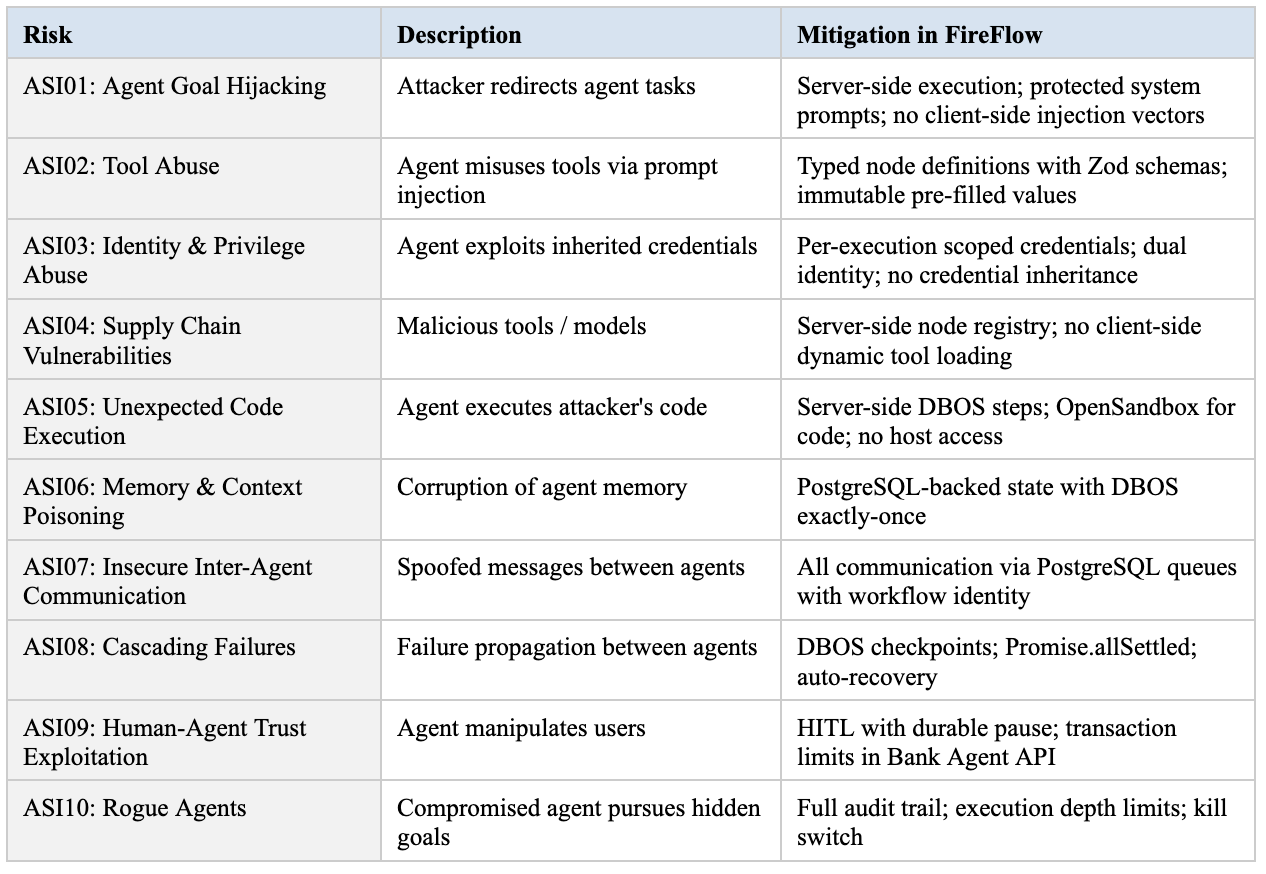
OWASP Top 10 for Agentic Applications (2026)
Developed by 100+ experts — the first specialized security framework for autonomous AI agents:
EU AI Act (Deadline for Financial Sector: August 2026)
Credit scoring, loan approval, fraud detection, and automated financial decisions are classified as high-risk AI systems under the EU AI Act. Fines: up to 7% of global annual turnover.

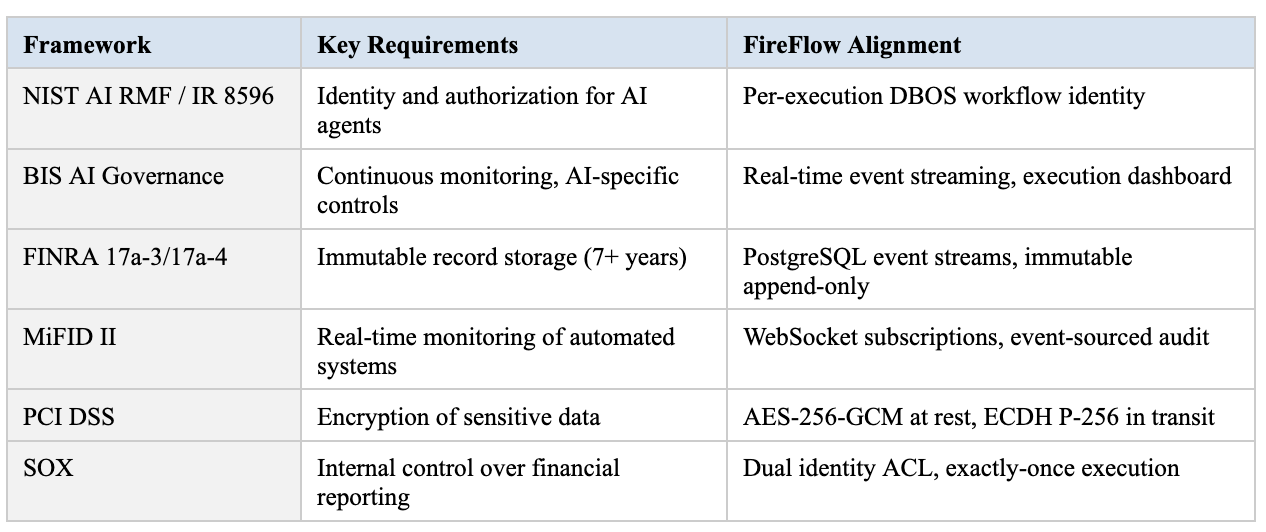
Additional Frameworks
What We Can Add
FireFlow’s architecture is designed for extensibility. The following are specific capabilities that can be added to strengthen banking deployments:
Granular Node-Level Permissions
Per-node access policies: ‘this node can only call the balance-check API, not the transfer API.’ Currently, tool access is controlled by the flow graph structure; this would add an explicit allowlist by node type.
Execution Budget Quotas
Hard limits on LLM token consumption, number of API calls, and execution time — per-workflow, per-user, per-period. Automatic execution termination on budget overrun.
Branch Protection Rules
Protection of the main branch in VFS: requiring review and approval before merge. Prevention of unauthorised flow changes in production.
Hardened Network Policy
Kubernetes NetworkPolicy + service mesh: explicit egress rules per worker pod. Only approved endpoints accessible.
Verifiable Execution Logs
Hashing event streams into a Merkle tree for tamper-evident audit. Any modification to historical records is cryptographically detectable.
Integration with External Secret Stores
Native adapters for HashiCorp Vault, 1Password, Infisical — direct connection to the bank’s existing secret infrastructure.
Conclusion
Core Principle
The agent is a controlled process inside your infrastructure — not an autonomous programme on the user’s machine.
Ten Independent Defence Layers:
[1. Execution Isolation] [2. Deterministic Engine] [3. Virtual FS]
[4. Secret Encryption] [5. Dual Identity & ACL] [6. HITL]
[7. Audit Trail] [8. Prompt Injection] [9. PII Anon.]
[10. User-Scoped API]
│
▼
[Bank Agent API — Final Independent Perimeter]
Financial rules that no agent, however compromised, can bypassIndependent defense layers guarantee that even if one layer is compromised, the others contain the breach:
Execution isolation — separate processes, no host access, Docker sandbox
Deterministic engine — formally proven, reproducible, exactly-once
Virtual filesystem — lakeFS-backed, role model, staged writes
Secret encryption — AES-256-GCM + ECDH, per-user keys, zero plaintext exposure
Dual identity & ACL — confused deputy protection, pre-filled value enforcement
Human-in-the-Loop — durable pause, three HITL mechanisms, kill switch
Audit trail — event-sourced, immutable, 25+ execution event types, time-travel debugging
Prompt injection defence — Plan-Then-Execute architecturally; ML classifiers and spotlighting as next step
PII anonymization — infrastructure for Anonymize→LLM→Deanonymize with kernel-level enforcement
User-scoped API access — ephemeral execution keys, forward secrecy, administrator cannot access credentials
Plus Bank Agent API as the final independent perimeter — enforcing financial rules that no agent, however compromised, can bypass.
Every major client-side AI agent was compromised between 2024 and 2026 (Claude Code, OpenClaw, Copilot, Cursor, n8n, Langflow).
The pattern is clear: the vulnerability is architectural, not implementation-specific. Server-side orchestration with layered defense is not simply safer — it is the only architecture that meets corporate security requirements for the financial sector.
Sources: IBM X-Force Threat Index 2026, OWASP Top 10 for Agentic Applications 2026, Check Point Research (CVE-2025-59536), NIST IR 8596, EU AI Act, Palo Alto Unit 42, Microsoft Security Blog, Gartner AI Agent Predictions 2027.